我们在使用webui的时候,会接触到各种启动参数,例如--autolaunch --xformers --medvram (启动完用默认浏览器打开,使用xformer,使用中度显存优化),那我们comfyui里是否也会有这些启动参数呢?答案当然是肯定的。那这些命令行分别是什么?官方没有文档。
但我们可以用一下方法获取
进入comfyui目录,右键 “在终端中打开” 输入
python main.py -h就可以查看所有命令。
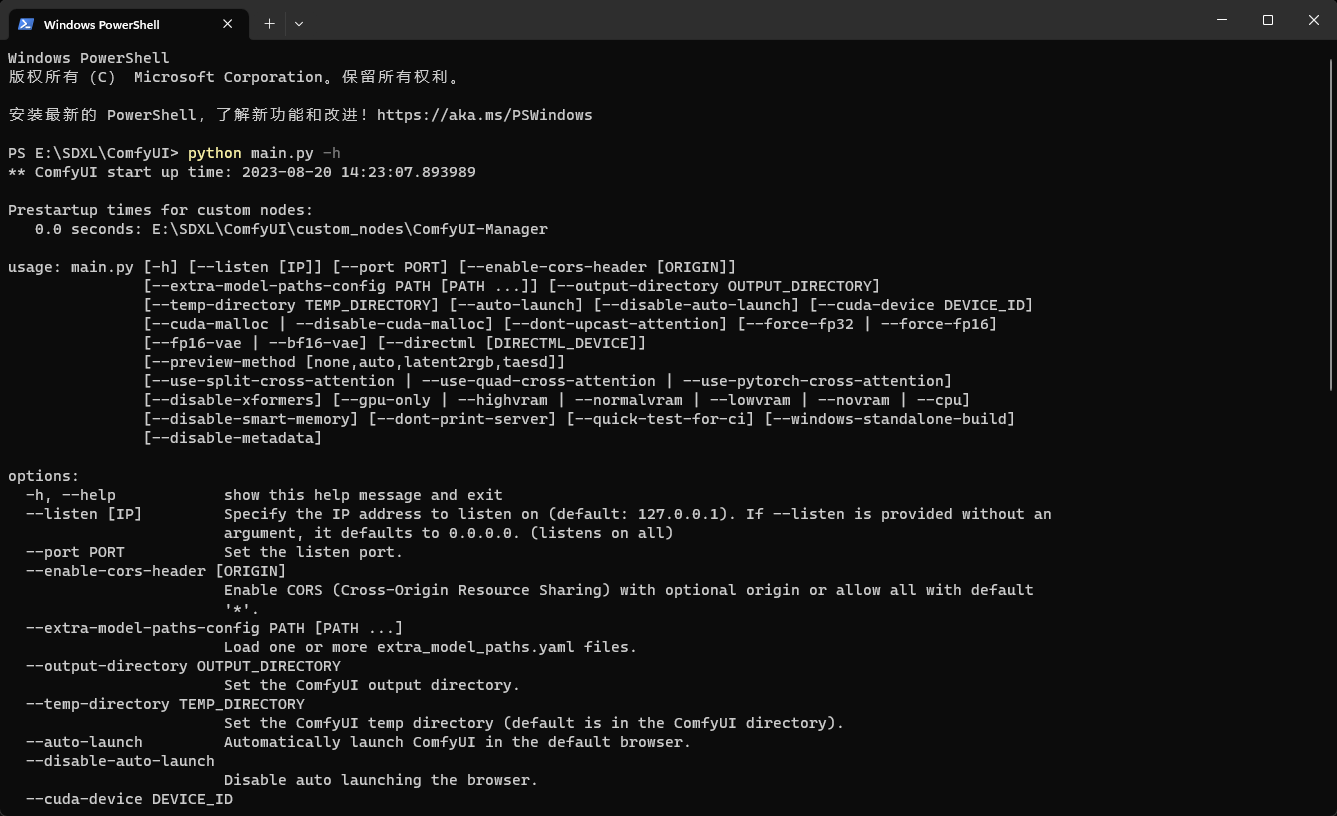
具体使用方法,我之前文章有说过,建一个txt文档,输入
@echo off
python main.py --auto-launch --listen另存为 run.bat (run可改成任意名称)。之后你点击这个批处理启动就可以。
这里面的--参数可以自己根据需求添加。
以下是启动参数介绍,这里我做一下中文解释,并把一些常用的标粗, comfyui默认启用xformers,性能不够时也会尝试使用lowvram,和tile vae帮你完成任务。对低性能机器比较友好。
--listen [IP]
指定要侦听的 IP 地址。只输入--listen 就监听所有ip,这个参数可以让你局域网的其他设备访问。具体参见这篇文章
--auto-launch
在默认浏览器中自动启动ComfyUI。
--highvram
默认情况下模型在使用后会卸载到CPU内存。这个选项将它们保存在 GPU 显存中。
--normalvram
如果 lowvram 自动启用,则会强制使用正常显存模式
--lowvram
强制将unet分成几部分以使用更少的vram完成任务。这里不建议强制添加参数,默认comfyui会在你性能不行时自动启用,交给系统去判断会更优
--port PORT
设置监听端口。
--extra-model-paths-config PATH [PATH ...]
加载一个或多个extra_model_paths.yaml 文件。
--output-directory OUTPUT_DIRECTORY
设置 ComfyUI 输出目录。OUTPUT_DIRECTORY 替换为你的输出目录
--cuda-device DEVICE_ID
设置此实例将使用的 cuda 设备的 ID。
--cuda-malloc
启用 cudaMallocAsync(默认启用torch 2.0 及更高版本)。
--disable-cuda-malloc
禁用 cudaMallocAsync。
--dont-upcast-attention
禁用upcast-attention。可以提高速度,但会增加出现黑色图像的机会。
--force-fp32
强制用 fp32 (如果你显卡很好)。
--force-fp16
强制 fp16。
--fp16-vae
在 fp16 中运行 VAE,可能会导致黑色图像。
--bf16-vae
在 bf16 中运行 VAE,可能会降低质量。
--directml [DIRECTML_DEVICE]
使用 torch-directml。
--preview-method [none,auto,latent2rgb,taesd]
采样器节点的默认预览方法。
--use-split-cross-attention
使用split-cross-attention 优化。使用 xformers 时忽略。
--use-quad-cross-attention
使用次quad-cross-attention优化。使用 xformers 时忽略。
--use-pytorch-cross-attention
使用新的 pytorch 2.0 交叉注意力功能。
--disable-xformers
禁用 xformers。
--gpu-only
在显卡GPU 上存储并运行所有内容(文本编码器/CLIP 模型等)。
--novram
当 lowvram 不够时。那我建议你换台机器吧。
--cpu
使用 CPU 处理所有事情(慢)。
--dont-print-server
不打印服务器输出。
--quick-test-for-ci
CI 快速测试。
--windows-standalone-build 独立环境构建使用参数,官方便携版(类似整合包,自带独立运行环境)就会用到这个参数。
--disable-metadata
禁止在图片文件中保存提示词数据。