1、【重要】【产品视角】AI 大模型的下一步,或许是 Google 早年的那种便宜方案
a)用软件换来的硬件的巨大成本优势,是 Google 早期成功不可忽略的因素。这段历史,会对现在的 AI 格局有所启发?
b)当年,Google没有买当时唯一正确的几万美金一台的高端服务器,而是在软木纸上,放上四小片主板、绑上硬盘、插上网卡;然后用软件,做了Google File System 分布的文件系统、在加上自己的 MapReduce 的框架,把计算可以分布(map)在这些小电脑上,然后把结果汇总(Reduce)……因为硬件便宜、算力足、存储便宜,这才足以支撑 PageRank 这样的巨大算力消耗,Google很快就从 Stanford 的一个无名小站,打败了当时的巨头(Lycos,AltaVista,InfoSeek)。
c)现在,用 Nvdia a100 的显卡堆出来的ChatGPT,固然帮助我们完成了第一步(从看不到可能性,到证明了可能性),就如同 Lycos 搭起来的昂贵的搜索引擎服务一样。但,是不是有 Google 这样的方式,用软件的方式疯狂的降低硬件成本的可能性呢?
2、【行业动态】Midjourney更新了very region(局部重绘)功能,相当于结合AI版的Photoshop和SD功能。
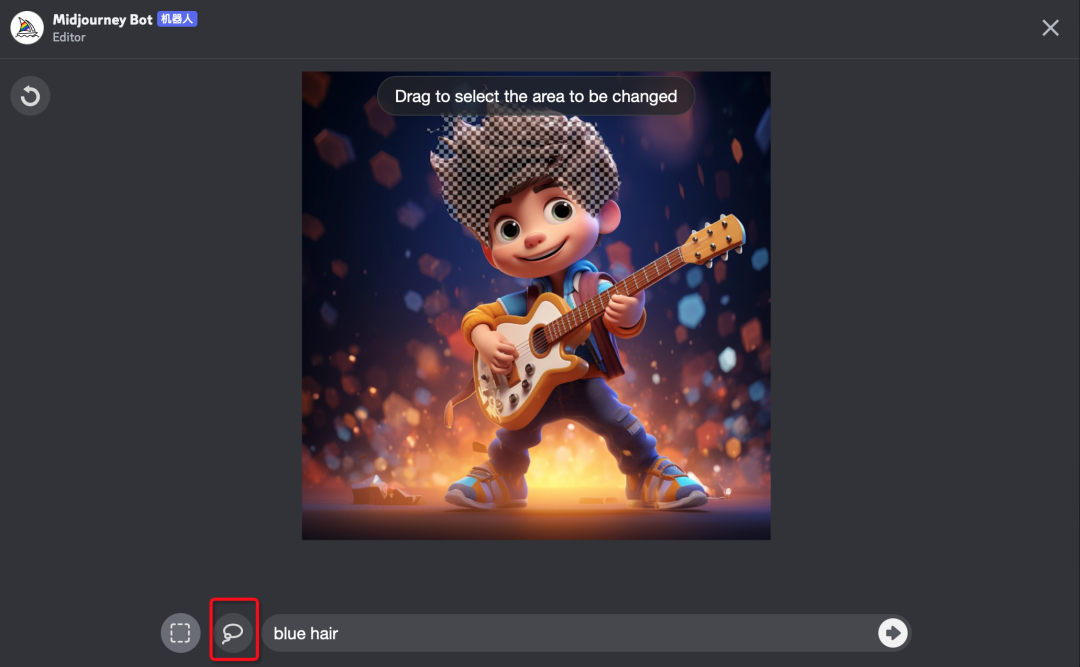
3、【重要】【技术视角】大模型研发核心:数据工程、自动化评估及与知识图谱的结合
a)现有大模型基本情况:分散在3个层级内,i)“买票乘坐”,包含有 GPT-4、 PaLM 等,提供API调用;ii)私有部署,包含有Flan-T5、Pythia等;iii)平民玩法,做一些领域微调得到一个私有部署模型,包含有Alpaka、Koala等。
b)现有大模型应用场景:S(阅读理解);M(语言学的解题或者情感分析、GRE考试)、L(语音或者推理的任务);XL(高考题或者其他一些更先进的工作);Next...(偏向于落地,解决更长文本的处理等问题)

c)中/英文主流大模型常用预训数据差别较大:i)英文:维基百科、书籍、论文期刊、WebText、Conmmon Crawl、The Pile及代码、论坛等;ii)中文:开源的评测数据、百科的三元组、社区QA、论坛讨论、Common Crawl等。
4、【行业动态】国内首个数学领域千亿级大模型MathGPT开启内测 by 好未来
a)通过文字或图片上传数学题,即可得到对话式的解答反馈
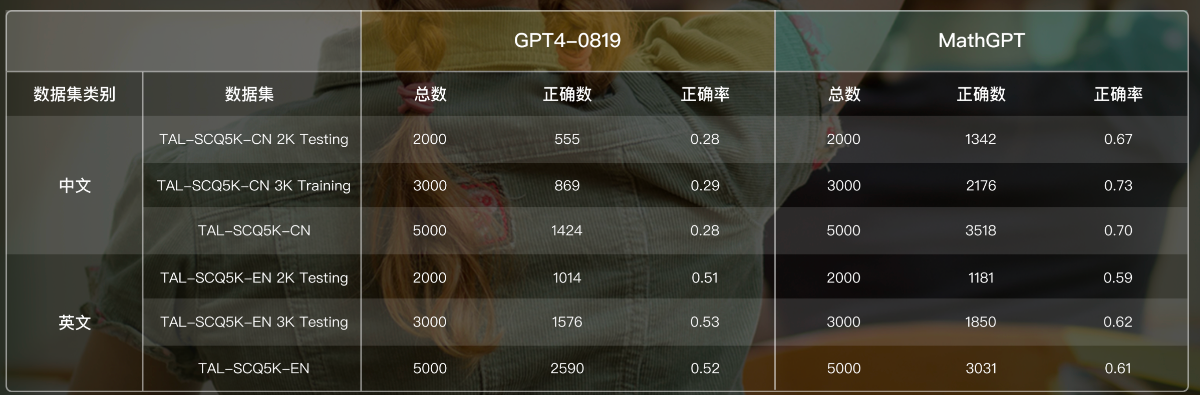
b)目前支持中文、英文版本的PC端和移动端体验,在部分数据集上有不错的表现。
c)申请内测入口详见官网链接。

5、【资源/工具】吴恩达 LLM finetune 新教程发布:详见deeplearning官网链接(需科学上网)。
----温馨提示----
当前早鸟价“60元/季度”,9月6日恢复原价“90元/季度”;升级到“AI产品经理大本营”社群会员,可抵扣60元,详见专栏介绍链接:https://xiaobot.net/p/ai01