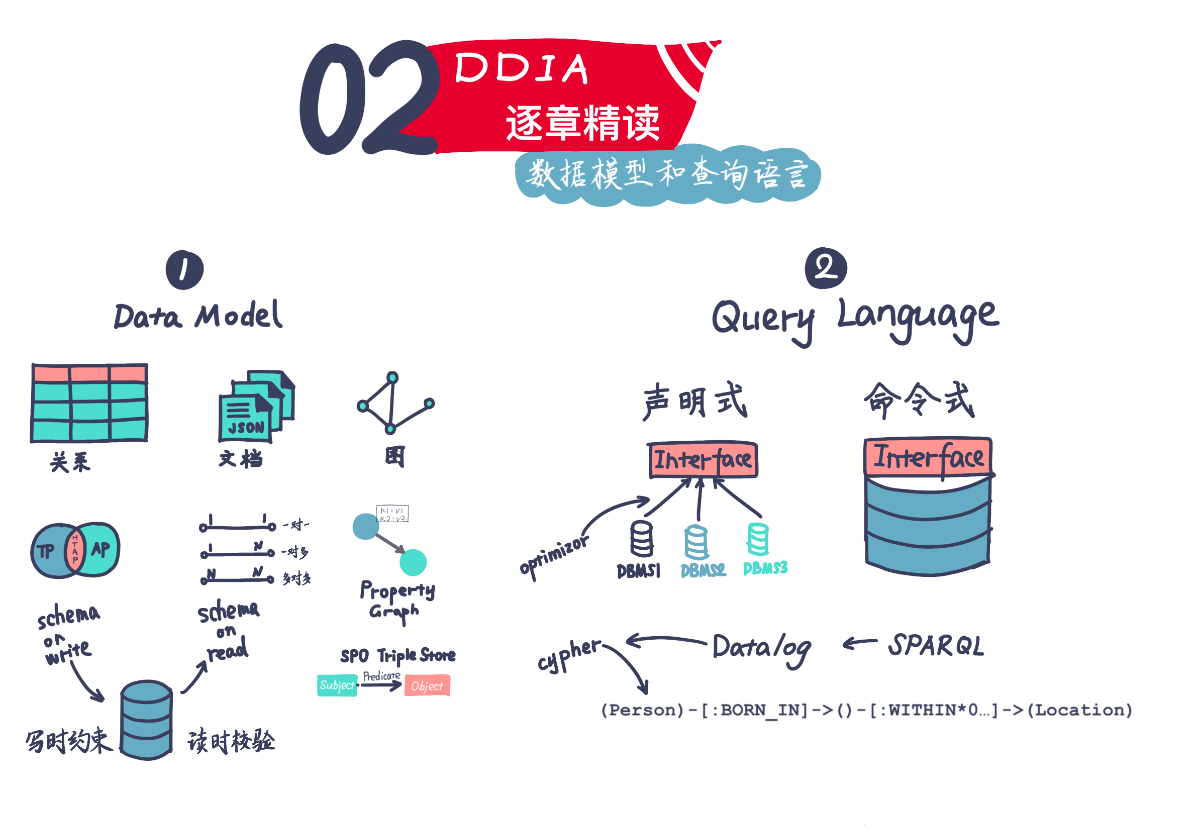
材料
中文参考:https://ddia.qtmuniao.com/#/ch02
b 站之前分享视频:
Youtube:
答疑
评论区打卡答疑:
第二章进度打卡。形式:YYYYMMDD-章节标题
第二章问题提问:形式:章节标题-问题。
在线答疑两次,时间定在:
答疑链接我到时候会提前放出来,可以关注本文或者群里通知。
微信答疑。其他零散问题随时在《DDIA 读书会》群里问,我每天会集中回答,我不在的时候大家自由讨论。
答疑问题整理
只整理了一个大概,更多可以去听音频原文。
https://www.xiaoyuzhoufm.com/episodes/6537737e75608281a9e8ae93
https://www.xiaoyuzhoufm.com/episodes/653fbe169cb67569a2f0e40a
1. 在使用图建模的时候,如何高效地找到入边和出边?
在分布式图数据库中,可以把点与其出边存在一个 Partition 中。但为了高效的找到每个点的入边,通常也会在一个 Partition 中将入边再存一次。但当然,这样一来,每条边就冗余的存了两次。
在单机基于外存(磁盘,SSD)的图数据库中,通常会点和边分成两个文件存。以 Neo4j 为例,会通过双向指针将一个点的所有入边和出边都串起来。
逻辑上的一个无向图:
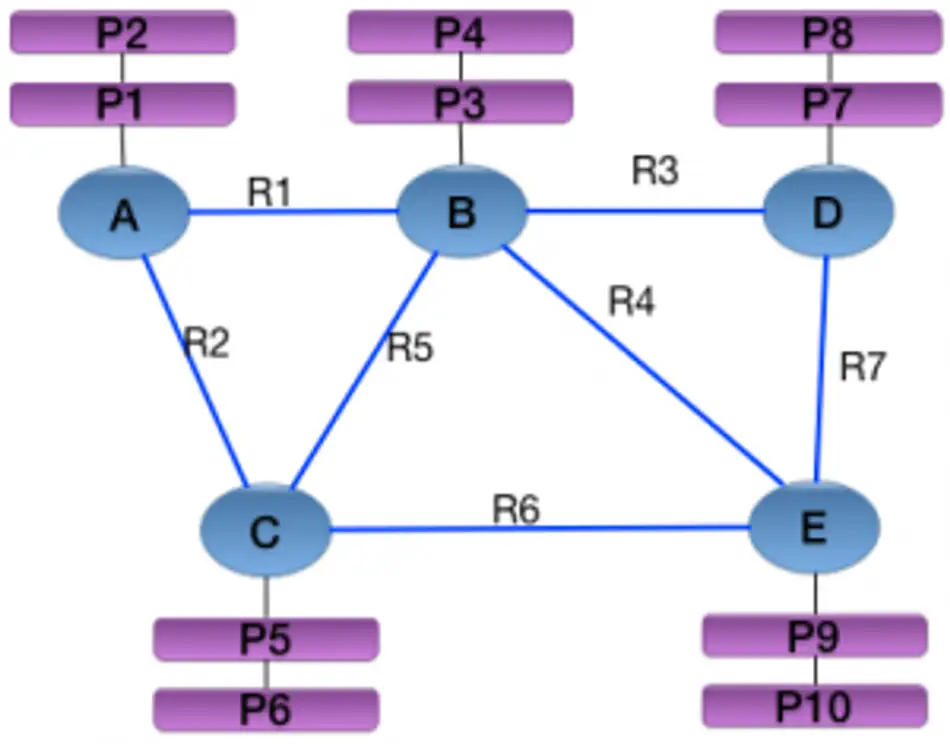
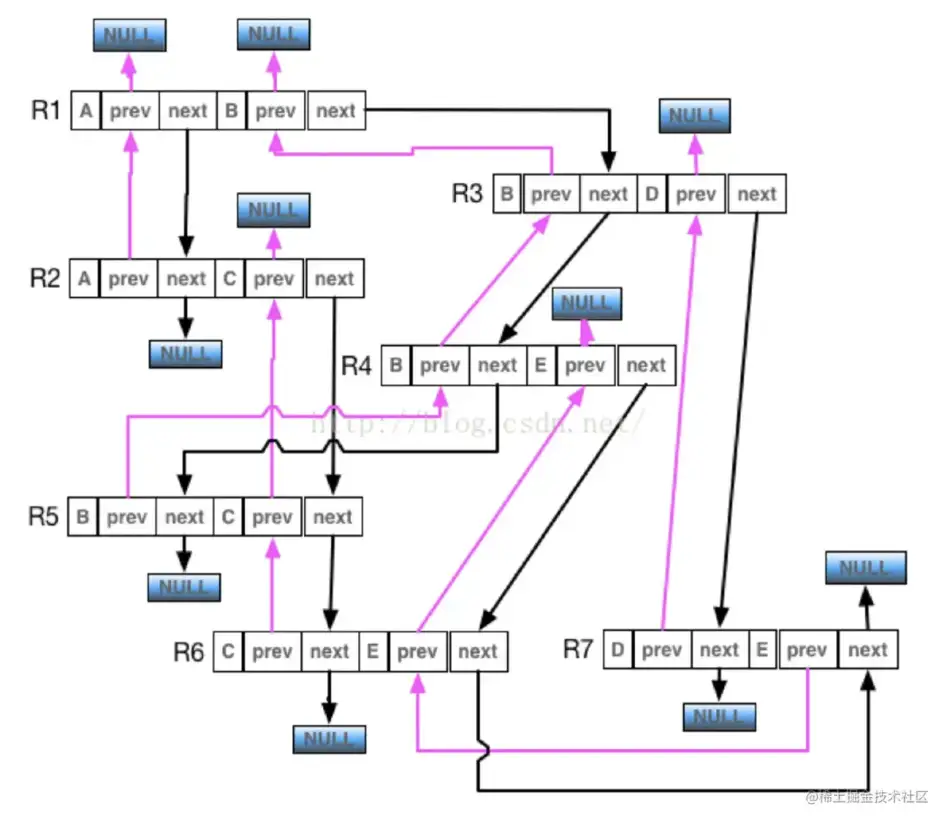
物理上会存成点文件、边文件和属性文件。下图是上面逻辑图边的物理存储,其核心在于将所有共点的边使用双向链表串起来,然后在点表里存储指向其所有邻接边的组成的双向链表的头尾。
在基于内存的图数据库中,就更好说了,比如常见的邻接表和邻接矩阵。以及基于邻接表的压缩表示方法:

这里解释下上图中第二种方法 CSR,这是一种针对不可变图的邻接表(上图中第三中方法)的压缩表示方法。基本原理是使用一个数组将所有出边代表的点拍平到一个数组中,然后用另外一个数组通过存下标的方式存储每个点出边列表的界限。
小结一下,就是:
使用某种方式将点和其出入边的入口建立联系
使用某种方式将一个点的所有出边和入边串起来
2. 我们的数据有很多冗余之后,有什么好的一致性保证的办法?
多副本间的一致性,工业界常使用共识协议(比如 Raft 或者 Paxos)来解决。
如果想让延迟更低一些、实现更简单一些,就需要适当放松一致性,这个后面章节也会讲。比如使用 Quorum,甚至更简单的主从复制。
现在比较火的向量数据库属于第二章的哪个模型?
第二章应该是没有讲向量模型。这个主要用在机器学习中应用,突出一个基于向量内积的“近似性”搜索。
基本思想是,首先会把所有的数据转化为 embeding 存到向量数据库中,然后查询到来时,会也先讲查询转化为 embeding,然后在向量池中进行搜索。
向量数据库所做的事情,就是合理的组织这些 embeding ,以支持快速的最相似的 TopN 搜索。并且,将 embeding 关联上其原本的一些属性,可以在搜索匹配上之后,把这些原来的属性返回。
由于在组织 embeding 的时候(hnsw算法),有时候会用图的方式进行组织,所以和图数据库有一些关联。
分布式数据库中的 CAP 怎么理解?
可以先看看这篇文章:https://www.qtmuniao.com/2020/02/16/not-cp-or-ap/
前面提到了一个分区间的一致性是什么意思?
主要是指分布式事务所需要保证的跨分区间数据的一致性,比如银行转账,一个分区的用户转出去了之后,另一个分区的用户一定要收到。不能因为实现问题出现钱凭空消失的情况。
另一个角度来理解,副本间的一致性是数据冗余带来的,分区间的一致性是跨对象操作带来的。前者是分布式实现时引入的,不能为用户可见。而后者是数据库一般都会提供的——事务——将一组对象的一组操作进行打包的能力。
分布式环境中,服务端会给客户端提供一些接口,如果某些请求出现异常或者耗时较长,阻塞其他请求怎么解决?
单机的话,多线程是必不可少的。可以用一个线程来分发请求到线程池中,前者只负责分发,后者负责处理,有点 IO 多路复用的感觉。这样一个请求阻塞暂时不会影响其他线程,多了几个并发度。
另一个方向是,可以通过增加超时判断等异常检测手段来把某些异常请求 kill 掉。也可以引入优先级机制,如果这些异常请求优先级不太高,可以把他们干掉,让他们重试。
面向对象和关系模型的不匹配是指?
是内存中的对象天然是嵌套的——一个对象可以作为另外一个对象的字段,这种嵌套方式和 Json 很像,但和关系模型不像。因为在 SQL 中,通常是每个表排平的,然后通过额外关系表+外键的方式来表达这种包含关系(一对多)——但表达的并不好。
换句话说,对于这种一对多的包含关系,关系型数据库通常表达的不是自然。
网络模型是一个什么样的模型,为什么被抛弃?
与现在的图模型相比,网络模型更加底层,不提供想 OpenCypher 这种声明式的查询语言。你需要记住你存的数据的结构,你才能在网络模型中进行遍历,有点像过程式。
第二章有没有讲可以用于 metric 监控场景的数据模型?
第二章主要讲了关系模型、文档模型和图模型。对于其他诸多数据模型都没有怎么涉及。包括 KV 模型、对象模型、时序模型、文件模型。其中指标监控场景就是时序模型或者流模型的典型应用场景,第十一章流处理有一些相关。
微服务时代、物联网时代,确实对监控需求比较大,因此流和时序其实也是提的比较多的。
另外,在大模型时代,专门针对 AI System 使用什么样的方式对数据进行建模呢?现在大家都也还在探索。相关的有向量数据库。
10. 图模型的一些应用场景?
NLP:知识图谱
银行:风控,反欺诈
互联网:推荐(协同过滤)
11. 文档存储如果只改其中一个字段,需要修改整个文档吗?
这取决于实现,类似关系数据库中的行存和列存。最基本的实现应该按 Document 粒度编码存在一块的,因此即使改一个字段,也需要读取整个文档。
书中提到有一些需求驱使着 NoSQL 的诞生,包括对高写入吞吐的需求;相对关系型数据库,NoSQL 为什么能满足高吞吐的写入需求?
英文书中原文是:
There are several driving forces behind the adoption of NoSQL databases, including:
A need for greater scalability than relational databases can easily achieve, including very large datasets or very high write throughput
这里的主要原因应该是关系型数据库是 schema-on-write,写时会做很多校验(比如各种字段类型是否满足、事务、一致性检查等等);NoSQL 通常是 schema-on-read,写的时候盲写,因此效率会高。
文中的一段内容“文档型数据库很擅长处理一对多的树形关系,却不擅长处理多对多的图形关系。如果其不支持 Join,则处理多对多关系的复杂度就从数据库侧移动到了应用侧。如,多个用户可能在同一个组织工作过。如果我们想找出在同一个学校和组织工作过的人,如果数据库不支持 Join,则需要在应用侧进行循环遍历来 Join”,意思是文档型数据库不擅长处理多对多的关系,举的例子没太明白?
比如说我们有:
按人组织的集合(Collection),也就是一个文档( doc )是一个人的简历信息;
按公司组织的集合,也就是一个文档是一个公司的基本信息;
在这种情境下,我们想找到属于某个公司的所有在职员工,以及这个公司一些基本信息。如果文档数据库不支持 join,就需要我们在应用层手动的把所有用户捞上来,然后逐个遍历,过滤在这个公司的人,然后再去公司集合中,捞出这个公司;再逐一和之前的相关用户结合。
如果没有 join,公司和员工间的这种多对多关系就只能在应用层手动处理。当然 MongoDB 是支持 join 的。只不过效率肯定不如只查询一对多关系(比如在上述情境中查询一个人的所有工作经历)的效率高。
14. 文件系统缓存是什么, 在用某种语言read file时, 还会从缓存中读取文件内容吗?

就是操作系统的 page cache。文件系统-> 外存,或者二级存储。page cache->内存,或者说主存。如果是 page cache 中已有的页,通过 read file 再去读时,是可以直接命中缓存的,不需要再去捞一遍了。
另外,在 Linux 6.3 测试,不同进程是可以共享 page cache 的。@Tang_D 同学做了相关的测试:https://gist.github.com/tang-hi/6555ec0a230c6f3602faf31963ee0e22
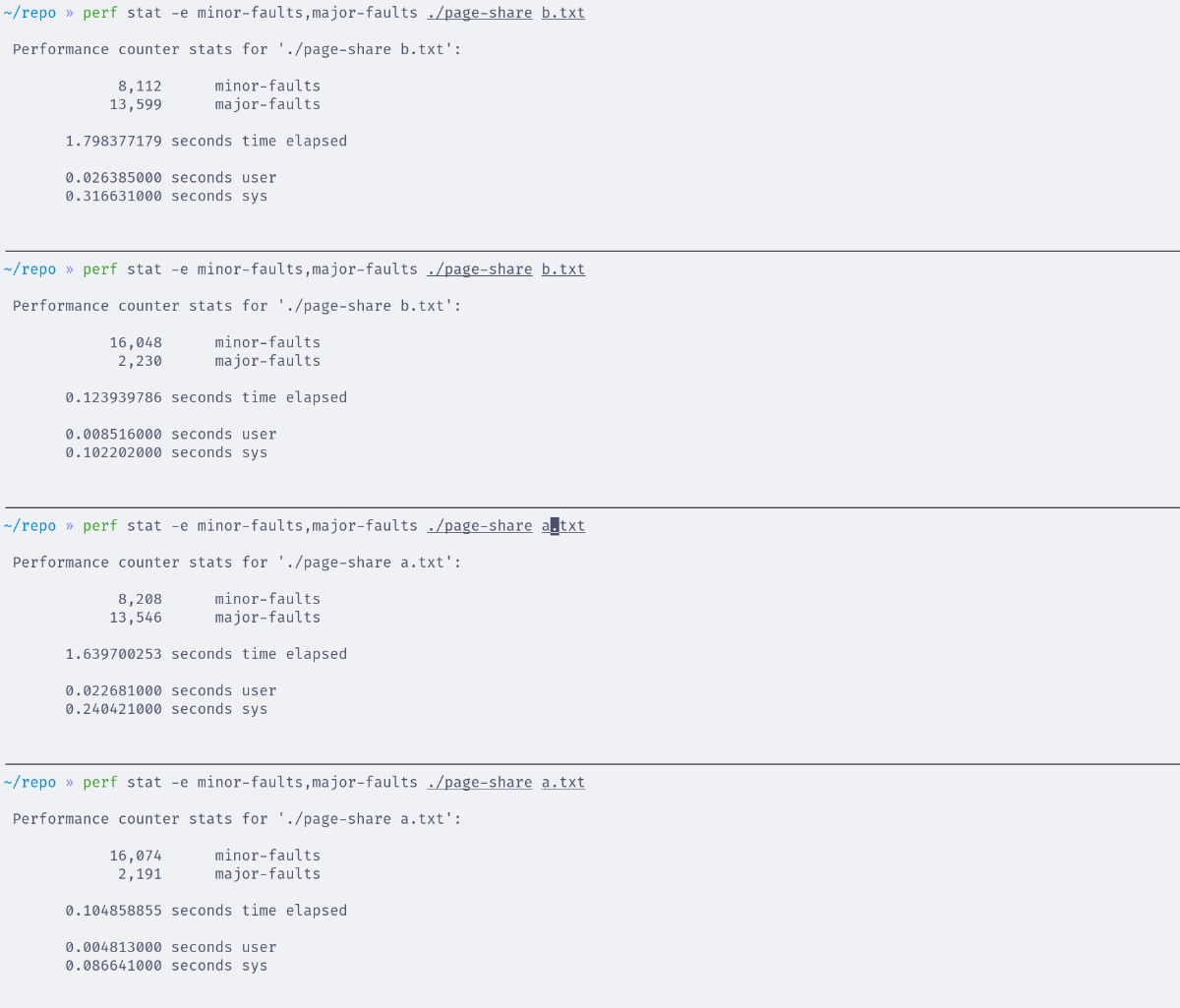
代码里用 mmap 是因为 read 没办法用 perf 测出去页率的:https://stackoverflow.com/questions/23317666/read-system-call-page-fault-doesnt-depend-on-file-size